

前提条件
- Kubernetes >= 1.23
安装Metrics-server
原文地址:k8s 安装metrics-server v0.7.1 - (sreok.cn)
创建Deployment
1 | cat > apache.yaml << EOF |
resources: limits: cpu: 500m requests: cpu: 200m
此字段是必须的
1 | kubectl apply -f apache.yaml |
1 | kubectl get svc # 记录svc端口,测试时使用 |
创建HPA
1 | kubectl autoscale deployment apache --cpu-percent=50 --min=1 --max=10 |

负载测试
安装测试工具
1 | yum -y install httpd-tools |
并发测试
1 | ab -c 100 -n 5000 http://10.20.13.140:32010/ |
-c 100 并发数
-n 5000 请求数
ctrl + c停止并发,
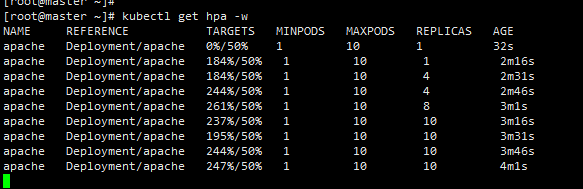
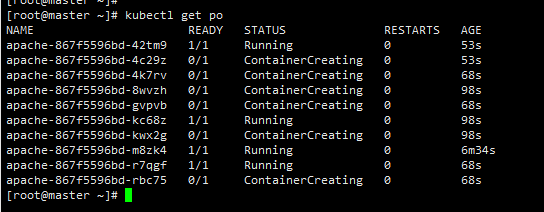
停止负载
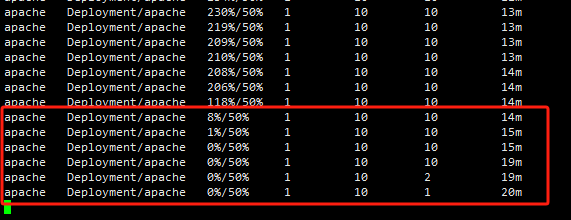
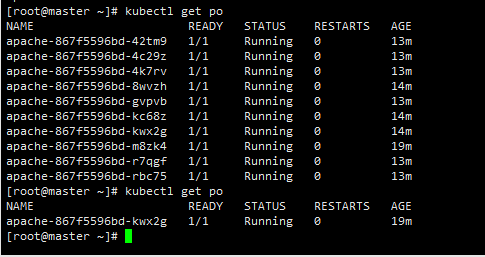
总结
HPA控制器会根据以下公式来计算需要的Pod副本数:
1 | 期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)] |
ceil是向上取整函数
根据以上Deployment配置,每个Apache Pod请求了200m的CPU资源(requests: cpu: 200m),并且设置了CPU资源限制为500m(limits: cpu: 500m)。
现在,我们设置HPA的目标CPU利用率为50%,这意味着我们希望每个Pod平均使用其请求CPU量的50%。
注意:百分比是根据pod的requests参数,由于每个Pod请求了200m的CPU,50%的利用率即为100m(200m的一半)。HPA将会监控所有Pod的CPU使用情况,并计算平均CPU使用率。如果平均CPU使用率超过100m,HPA就会开始扩容。