NVIDIA官方文档:NVIDIA/k8s-device-plugin:用于 Kubernetes 的 NVIDIA 设备插件
前提条件
安装NVIDIA Container Toolkit
官方地址:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
yum install -y nvidia-container-toolkit更新运行时
docker
nvidia-ctk runtime configure --runtime=docker
systemctl restart docker无根模式下运行的docker
nvidia-ctk runtime configure --runtime=docker --config=$HOME/.config/docker/daemon.json
systemctl --user restart docker
nvidia-ctk config --set nvidia-container-cli.no-cgroups --in-placeContainerd
nvidia-ctk runtime configure --runtime=containerd
systemctl daemon-reload
systemctl restart containerd仅用于nerdctl无需配置,直接运行nerdctl run --gpus=all
如果以上修改不生效,修改默认运行时
# 编辑
/etc/containerd/config.toml搜索
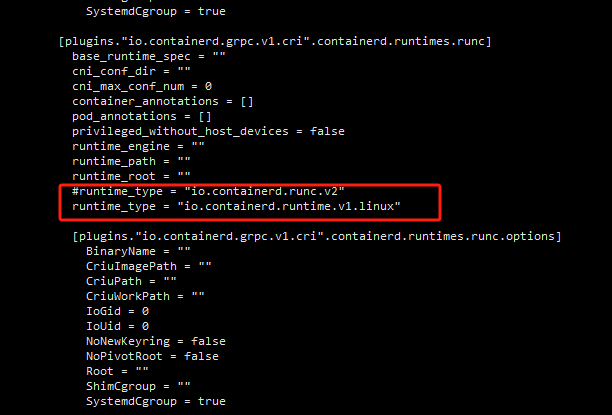
plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc
runtime_type = "io.containerd.runc.v2"改成io.containerd.runtime.v1.linux搜索
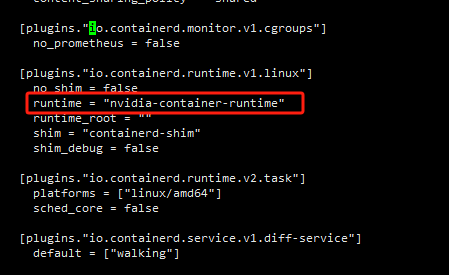
io.containerd.runtime.v1.linux
runtime = "runc"改成runtime = "nvidia-container-runtime"
systemctl daemon-reload
systemctl restart containerdCRI-O
nvidia-ctk runtime configure --runtime=crio
systemctl restart crio部署nvidia-device-plugin
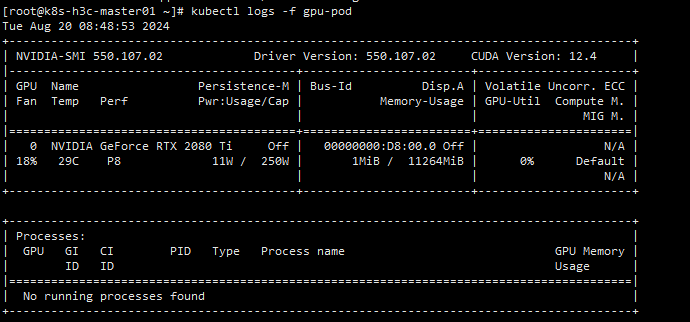
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.16.2/deployments/static/nvidia-device-plugin.yml查看GPU所在节点的pod日志
正常情况(将GPU注册到kubelet):
I0820 08:26:47.926058 1 main.go:317] Retrieving plugins.
I0820 08:26:51.674618 1 server.go:216] Starting GRPC server for 'nvidia.com/gpu'
I0820 08:26:51.682183 1 server.go:147] Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
I0820 08:26:51.690851 1 server.go:154] Registered device plugin for 'nvidia.com/gpu' with Kubelet未找到GPU(尝试将nvidia修改为默认运行时):
I0820 08:26:53.370854 1 main.go:317] Retrieving plugins.
E0820 08:26:53.370997 1 factory.go:87] Incompatible strategy detected auto
E0820 08:26:53.371004 1 factory.go:88] If this is a GPU node, did you configure the NVIDIA Container Toolkit?
E0820 08:26:53.371010 1 factory.go:89] You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites
E0820 08:26:53.371016 1 factory.go:90] You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start
E0820 08:26:53.371021 1 factory.go:91] If this is not a GPU node, you should set up a toleration or nodeSelector to only deploy this plugin on GPU nodes
I0820 08:26:53.371029 1 main.go:346] No devices found. Waiting indefinitely.更新运行时后,重启device-plugin daemonset
kubectl rollout restart ds -n kube-system nvidia-device-plugin-daemonset测试
# gpu节点打标签
kubectl label nodes k8s-dell-r740-worker01 nvidia.com/gpu=trueapiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: IfNotPresent
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1
command: ['nvidia-smi']
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
#nodeSelector:
# viadia.com/gpu: "true"查看pod日志